How to Build an Operational Datastore With S3 and Redshift? Step-by-Step Guide
Operational data is produced by day-to-day business activities like transactions, user interactions, IoT sensors, etc. This high-velocity data needs specialized infrastructure for storage and analysis.
Operational data stores built on Amazon S3 and Amazon Redshift provide a powerful and flexible cloud architecture for real-time analytics.
In this step-by-step guide, we will dive into how to leverage these AWS services to build a performant and scalable operational datastore.
What is an Operational Datastore?
An operational datastore is optimized for storing and processing high volumes of real-time operational data. Key aspects include:
- Fast data ingestion from various sources
- Real-time analysis with minimal latency
- Flexible data model to accommodate variably structured data
- High availability and durability of data
- Scalability to handle data spikes
Unlike traditional data warehouses focused on business intelligence, operational datastores enable real-time decision-making by reducing data-to-insight times.
Benefits of S3 and Redshift
Amazon S3 and Redshift make an excellent combination for building operational datastores due to:
- High scalability – Both S3 and Redshift can scale storage and compute as per data volumes ingested.
- Performance – Redshift delivers fast query performance for real-time analytics by using columnar storage, MPP architecture, and advanced query optimization.
- Cost-effectiveness – You only pay for the resources you use. The separation of storage and computing allows for optimizing costs.
- Durability – Data stored in S3 and Redshift is replicated for high durability.
- – The S3 data lake allows capturing variably structured data which can be processed for Redshift.
- Managed services – Redshift and S3 are fully managed, reducing operational overheads.
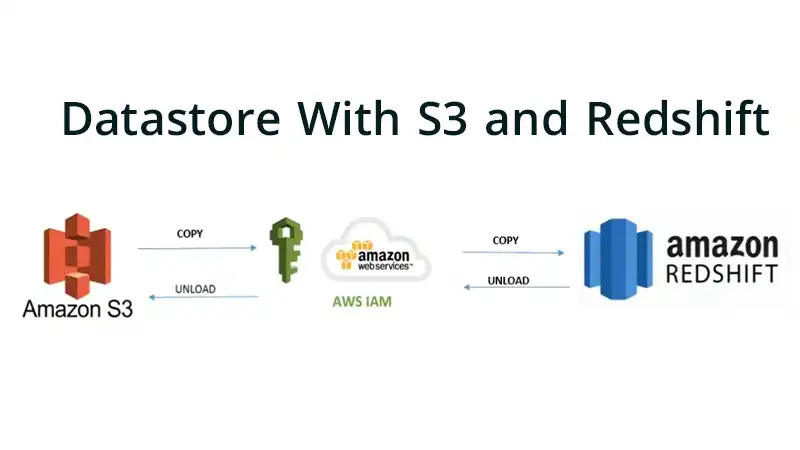
Architecture Overview
A typical S3 and Redshift architecture looks like this:
- Operational data from various sources is streamed to the S3 data lake.
- Extract, transform, load (ETL) jobs process S3 data and load into Redshift.
- Redshift clusters store curated datasets for real-time analytics.
- BI tools query Redshift and visualize insights.
- Elastic compute resources auto-scale to match data volumes.
The decoupled storage and compute provide flexibility to scale resources independently.
Implementation Steps
Follow these key steps to implement an operational datastore with S3 and Redshift:
- Design the Analytical Data Model
The first step is to design the analytical data model optimized for your business reporting needs.
- Identify the key entities like customers, products, transactions etc.
- Define relationships between entities using foreign keys.
- Choose appropriate data types – optimize for range filters and aggregations.
- Normalize appropriately to avoid redundancies and inconsistencies.
- Include required dimensions, facts and aggregation columns.
- Model time series data for trended analysis using date dimensions.
The output is a relational schema optimized for analytics and business intelligence.
- Create Database and Schema in Redshift
Once the data model is ready, we can create a database and schema in Amazon Redshift to store the tables.
- Use the AWS console to create a Redshift cluster with optimal node type and count.
- Create a database to logically group tables.
- Define a schema corresponding to the data model.
- Specify dist and sort keys based on queries.
This prepares Redshift for loading and querying the data.
- Set Up Data Lake Storage on S3
We need to stage the source data on Amazon S3 before loading it into Redshift.
- Create an S3 bucket for the data lake.
- Logically partition the bucket into raw, processed, and curated zones.
- Apply appropriate data lifecycle policies for transition and expiration.
- Set up access controls for security and privacy.
This provides a durable and scalable data lake for staging data.
- Build ETL Process
Develop ETL process to extract data from sources, transform, and move to Redshift.
- Extract data from operational systems using APIs, batches, or streaming.
- Cleanse, validate, normalize, and conform data to the target model.
- Use Glue crawlers to infer schema and defined mappings.
- Insert data into Redshift tables using copy commands or API integration.
Robust ETL ensures high-quality data is loaded into the warehouse.
Develop Business Intelligence Dashboards
Connect your visualization layer to Redshift to build reports and dashboards.
- Use tools like Quicksight to connect and model data.
- Build interactive reports, charts, pivot tables, and dashboards.
- Schedule refresh to update with the latest data.
- Control access to data via row-level security.
Rich analytics uncovers business insights from the data.
Monitor and Maintain Data Pipeline
Ongoing monitoring and maintenance ensures the health of the data pipeline.
- Monitor data volumes, ETL metrics, and pipeline errors.
- Tune ETL queries and Redshift performance periodically.
- Scale Redshift clusters to match data growth.
- Manage data retention policies and purging.
- Update models, and mappings as needs evolve.
Use Cases
Typical use cases for an S3 and Redshift operational datastore include:
- User analytics: Analyze user journeys, feature usage, and other operational metrics for product improvement.
- Fraud detection: Detect fraudulent transactions, account activity, etc. in near real-time.
- IoT analytics: Ingest and process streams of sensor data for monitoring and analytics.
- Supply chain optimization: Gain insights into material flow, inventory, and logistics for efficient operations.
- Customer 360 analytics: Build composite customer profiles by integrating data across departments and channels.
Best Practices
Follow these best practices when architecting your S3 and Redshift operational datastore:
- Choose the right distribution and sort keys in Redshift for optimized performance.
- Partition large tables into smaller ones for better parallelism and fewer VACUUM ops.
- Compress tables and columns to reduce storage requirements.
- Isolate workloads by allocating dedicated clusters per usage pattern.
- Implement IP whitelisting and VPC endpoints for security.
- Backup critical data in S3 regularly.
FAQs – Frequently Asked Questions and Answers
- Does Redshift support unstructured data as well?
Answer: Redshift is optimized for structured and semi-structured data. For completely unstructured data, storing it directly in S3 and running analytics using Athena would be more efficient.
- How do you ensure data consistency between S3 and Redshift?
Answer: Use ETL best practices like committing data only after successful loads to Redshift. Implement reprocessing pipelines to reconcile gaps.
- Can you use other AWS databases like DynamoDB for an operational datastore?
Answer: Yes, DynamoDB can complement S3 and Redshift for certain operational workloads requiring key-value access to real-time data.
To Conclude
Combining the scale and flexibility of S3 with the performance of Redshift provides a powerful platform for real-time operational analytics. Planning the architecture, schemas, ETL processes and integrations is key for smooth implementation.
With robust monitoring and optimizations, an S3-Redshift datastore can deliver the performance and availability required for mission-critical workloads.