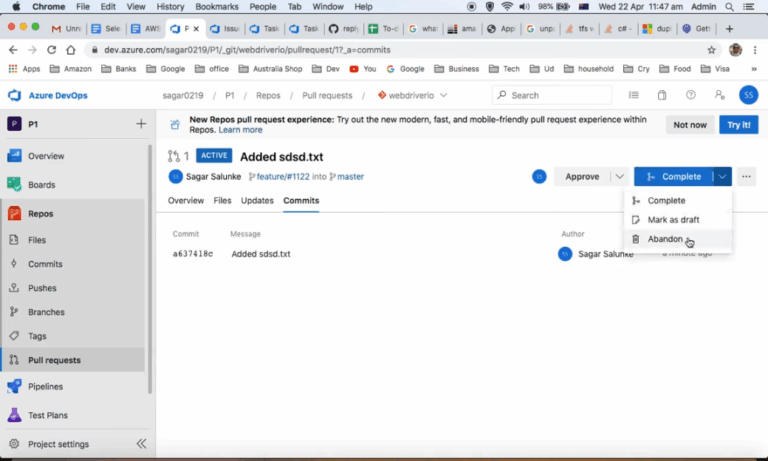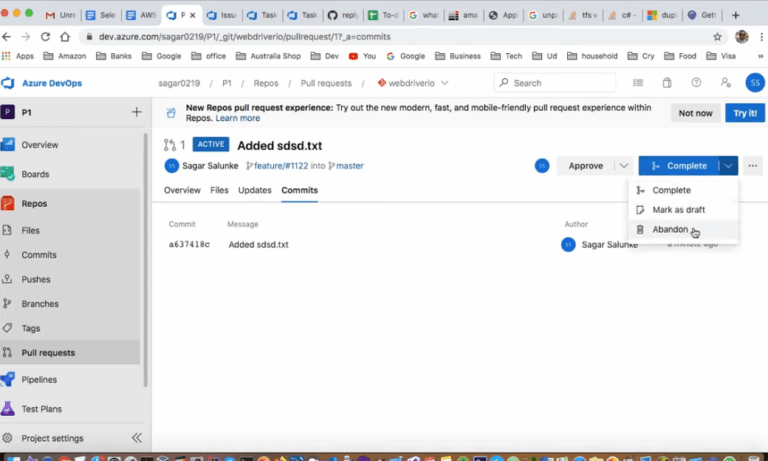
Multiple YAML Build Pipelines in Azure DevOps
Azure DevOps is a powerful platform that provides a comprehensive suite of tools for managing the entire software development lifecycle. One of its standout features is the support for YAML-based build pipelines, which allows developers to define their build processes as code. This article will explore how to set up multiple YAML build pipelines in…