Is Amazon Redshift a Relational Database (Ultimate Explanation)
Amazon Redshift, a fully managed AWS service, is one of the most popular choices in the evolving data management and analytics landscape. Due to its ability to handle large-scale data, the question often arises: Is Amazon Redshift a relational database?
Theoretically, Redshift is a relational database management system (RDBMS) designed specifically for data warehousing and analytics. But unlike traditional databases, it uses a columnar storage model. Hence, it is best suited for business intelligence applications that need fast and scalable query performance.
In this article, we shall try to shed light on the role of Amazon Redshift in modern data analytics and answer how it differs from other services. So, without further delay, let’s dive in.
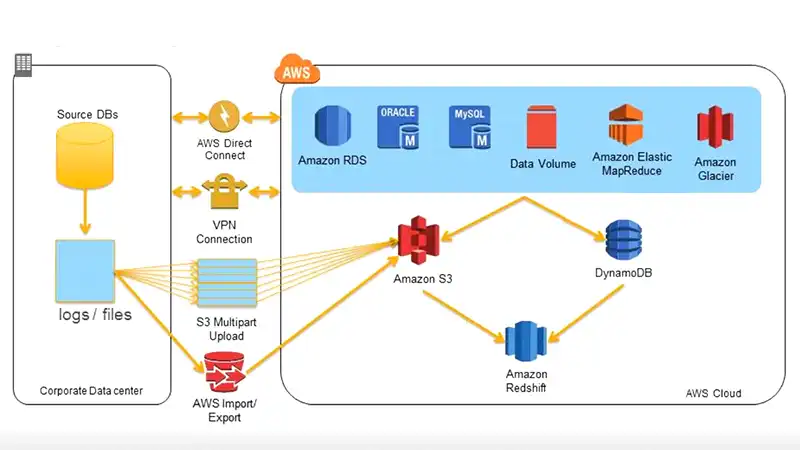
Is Amazon Redshift a Database?
Calling Redshift a database is technically correct, but the term ‘data warehouse’ suits it best. Yet, it is far from being a regular data warehousing service. It is more like a high-performance database that offers Online Analytical Processing (OLAP).
For those unaware, OLAP databases can perform multidimensional analysis of critical data. It is a feature generally available with data warehouses such as Snowflake and BigQuery. Due to this, you can get quick access to data like sales figures and consumer demographics for mining and analysis.
OLAP databases differ from conventional OLTP databases that usually let you store and manage transactional data. The functionality of OLTP is to process transactions like inserts and updates quickly and efficiently using normalized data structures. However, it cannot run complex analytical processing like OLAP.
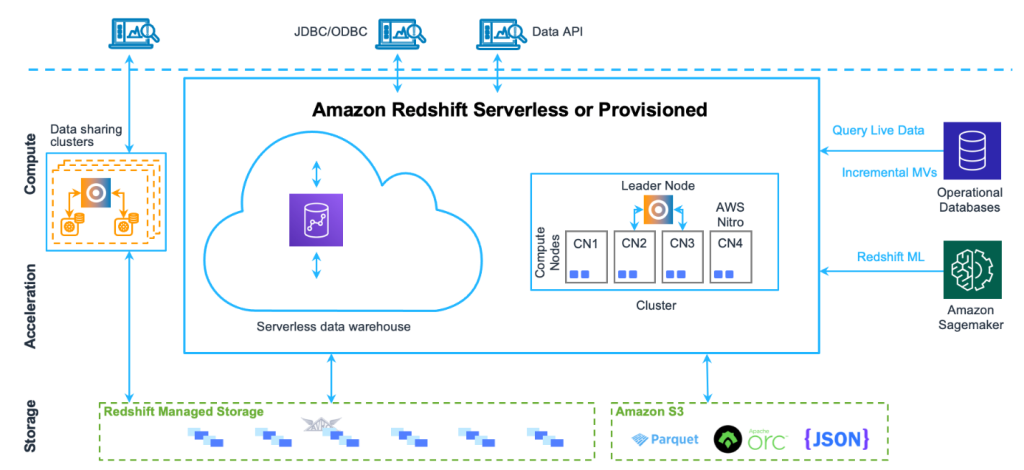
Besides, Redshift uses different methods like multi-node data distribution and compression to boost its performance. It uses PostgreSQL with add-on features like auto compression, parallel processing, and data encryption at rest. That means Amazon Redshift is a better alternative to traditional SQL databases.
Is Redshift Relational or Non-Relational?
To determine whether or not Redshift qualifies as a relational database, we need to compare its architecture with the key characteristics of a relational database.
1. Data Organization
Traditional relational databases can handle transactional workloads by storing data in rows. In contrast, Amazon Redshift uses a columnar storage strategy for quickly accessing data attributes and delivering highly optimized analytical processing.
2. Data Schema
Like all relational databases, Redshift also depends on schemas for structuring and organizing data. It lets you define tables with schemas, impose data types, and use primary and foreign keys to create relationships between tables.
3. SQL Support
Amazon Redshift supports SQL, which is the standard language for relational databases. So, you can run SQL queries to insert, modify, and analyze stored data.
4. ACID Compliance
Redshift is an OLAP database instead of a full-fledged OLTP. Hence, it may not provide transactional integrity on the same level as traditional relational databases.
5. Scalability and Performance
Most relational databases tend to struggle when it comes to handling massive datasets and complex analytical queries. Fortunately, Amazon built Redshift from the ground up to perform well in such scenarios. It offers horizontal scalability for better handling when the query workload grows significantly.
Final Verdict: Is Amazon Redshift a Relational Database?
Redshift is technically a relational database, although not in a traditional sense. For example, like most relational databases, it has support for SQL and Data Schema. However, Redshift separates itself through columnar storage, excellent analytical processing via OLAP, and an affordable pay-as-you-go cost structure.
Frequently Asked Questions
Is Redshift relational or columnar?
Amazon Redshift is a relational database management system with a column-based storage structure. Unlike traditional databases, it stores data in columns and is compatible with other RDBMS systems while providing the advantages of a columnar database.
Is Redshift an OLAP database?
Addressing Redshift as a data warehouse is the most appropriate way, although it is technically an OLAP database. That is because it can perform online analytical processing on large chunks of data.
Is it Redshift SQL or NoSQL?
Amazon Redshift uses PostgreSQL with additional capabilities like managing and processing large amounts of analytical data.
Conclusion
To conclude, it may be more accurate to describe Amazon Redshift as a specialized relational database management system tailored for data warehousing and analytical workloads. We hope that answers your question. Thank you for staying tuned! For further queries, feel free to comment below.