How to Use Hive Metastore in Spark | A Complete Guide
Apache Spark is a powerful open-source distributed system that enables large-scale data processing. One of its key components, Spark SQL, offers a programming interface for seamless data manipulation. And by integrating it with Hive, a fault-tolerant data warehouse system, you can upscale its analytical capabilities.
The Hive Metastore plays a crucial role in this integration, serving as a central repository for metadata associated with Hive tables. In this article, we’ll explore how to use Hive Metastore in Spark to manage metadata, leverage existing Hive tables, and enhance the overall data processing experience.
Why Use Hive Metastore in Spark?
Before setting up and integrating Hive Metastore with Apache Spark, here’s an overview of why this incorporation is a strategic decision.
Streamlining Metadata Management
By utilizing Hive Metastore, Spark applications can streamline metadata management. This means that metadata, such as schema information, can be centrally managed and accessed by different Spark applications, promoting consistency and reducing redundancy.
Enhancing Scalability and Performance
Centralized storage of metadata in Hive Metastore enhances scalability and performance. As metadata is stored separately from the compute resources, Spark applications can scale efficiently without the burden of managing metadata locally. This separation of concerns contributes to better performance and resource utilization.
How to Connect to Hive Metastore Using Spark?
To use Hive Metastore in Spark, you need to ensure that Spark is configured to connect to the Hive Metastore service. This involves specifying the Hive Metastore URI and other relevant configurations. Below is a basic example of how you can set up Hive Metastore in Spark.
1. Include Hive Dependencies
When launching your Spark application, ensure that you include the necessary Hive dependencies. You can achieve this by adding the following configuration:
–packages org.apache.spark:spark-core_2.11:2.4.8,org.apache.spark:spark-sql_2.11:2.4.8 –conf spark.sql.hive.metastore.version=2.3.7
2. Configure Hive Metastore
Specify the Hive Metastore URI in your Spark application. This can be done by setting the spark.sql.warehouse.dir property.
val spark = SparkSession.builder
.appName("SparkWithHiveMetastore")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()3. Start Spark Session with Hive Support
Ensure that you enable Hive support when creating a Spark session.
val spark = SparkSession.builder
.appName("SparkWithHiveMetastore")
.enableHiveSupport()
.getOrCreate()How to Configure Hive Metastore With Spark Using HDInsight on AKS
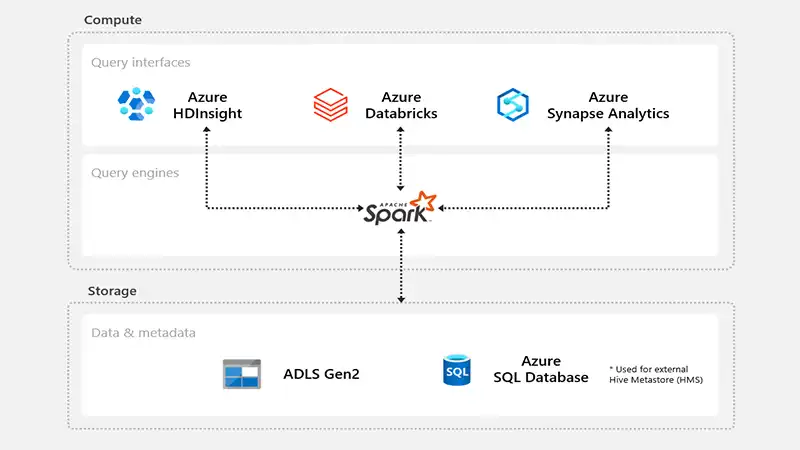
HDInsight on AKS stands as a dependable and secure Platform as a Service (PaaS) that is entirely managed and operates on Azure Kubernetes Service (AKS). It provides users with the capability to establish connections to external metastores. This integration facilitates seamless connectivity between HDInsight and other services within the ecosystem.
Assuming that you have created your Azure SQL database and a key vault to store credentials, here’s how to configure Spark to use Hive Metastore.
- Go to the HDInsight on AKS Cluster pool to initiate the creation of clusters.
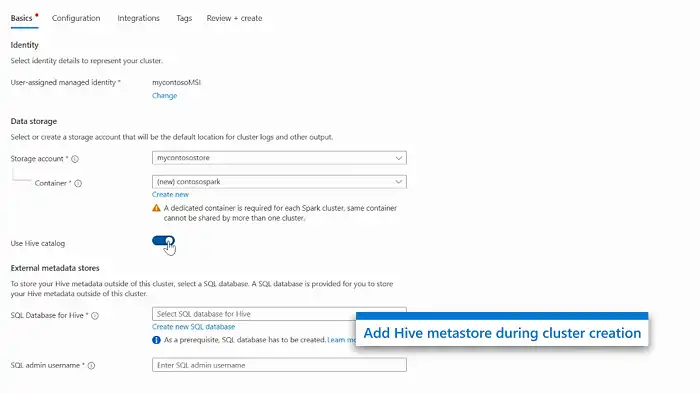
- Toggle the button to enable the addition of an external Hive metastore and input the required details.
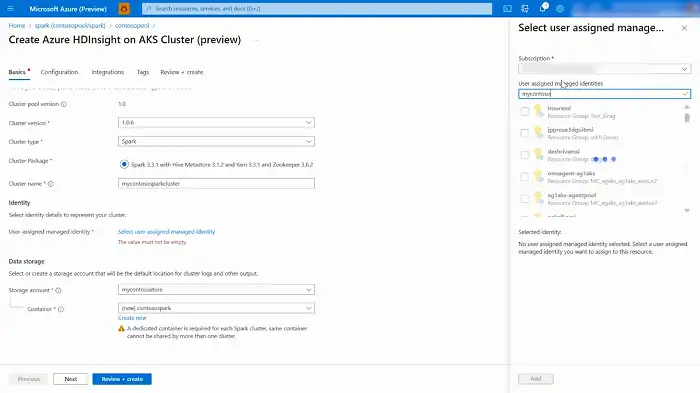
- Ensure that the remaining information is completed in accordance with the cluster creation guidelines for an Apache Spark cluster in HDInsight on AKS.
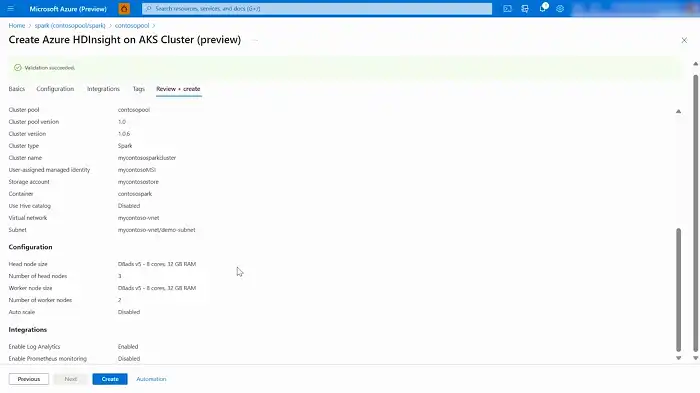
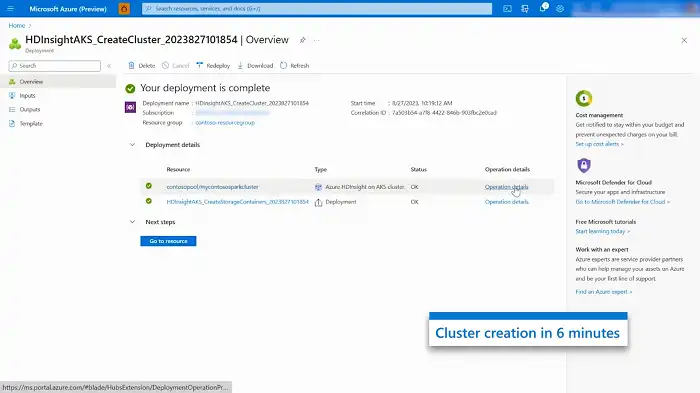
- Proceed to click on “Review and Create” to finalize the setup.
Interacting with Hive Tables in Spark
Once the setup is complete, you can start using Hive Metastore in Spark for managing tables and executing queries. Here are some common operations:
1. Querying Hive Tables
You can use the following command in your Spark shell to read a hive table. Make sure to replace the name of the table with your desired one.
val result = spark.sql("SELECT * FROM your_hive_table")
result.show()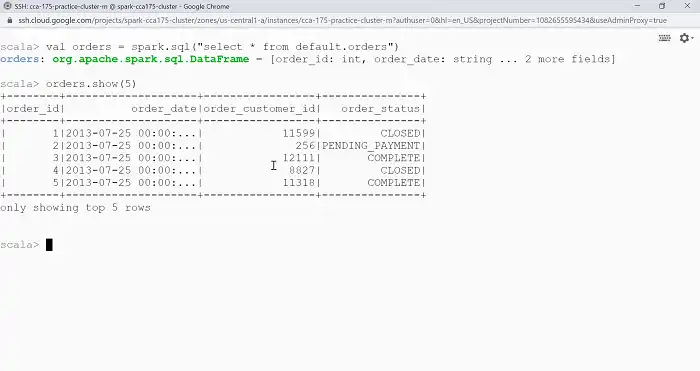
2. Writing to Hive Tables
You can easily write DataFrames into Hive tables using the following code snippet.
val dataFrame = // Your DataFrame
dataFrame.write.saveAsTable("your_hive_table")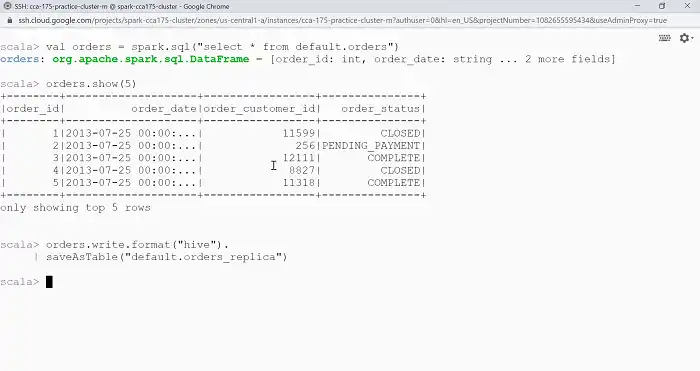
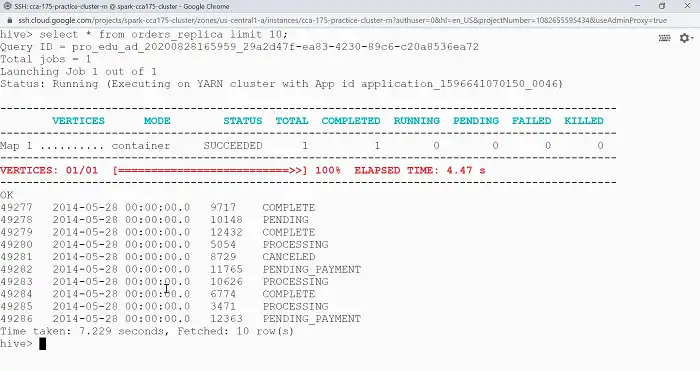
3. Managing Partitions
Hive supports table partitioning for improved query performance. You can leverage this feature in Spark as well:
val partitionedDF = // Your partitioned DataFrame
partitionedDF.write.partitionBy("partition_column").saveAsTable("partitioned_hive_table")Can I use Hive Metastore with Spark without configuring it explicitly?
While Spark can be used without configuring Hive Metastore explicitly, setting it up enhances metadata management and enables seamless integration with Hive.
Is it possible to connect Spark to a remote Hive Metastore service?
Yes, by providing the correct Hive Metastore URI in the Spark configuration, you can connect to a remote Hive Metastore service.
Which is faster: Hive or Spark?
Apache Spark is generally considered faster than Apache Hive for data processing tasks. Spark’s in-memory processing capabilities and optimized execution engine contribute to its speed advantage over Hive, which traditionally relies on MapReduce for processing.