Data Anonymization vs Data Masking | Comparison Guide
Data privacy and security are critical concerns for organizations today. As data collection expands, so does the risk of data breaches that expose sensitive customer information. Data anonymization and data masking are two techniques used to protect personal data by altering it to prevent the identification of individuals.
Here we will differentiate between data anonymization and masking, their use cases, and best practices for implementing each technique.

What is Data Anonymization?
Data anonymization is the process of removing or altering personally identifiable information (PII) in a dataset to prevent identifying individuals. This irreversibly de-identifies the data.
Some techniques used in data anonymization include:
- Generalization – replacing specific values like names or ages with broader categories. For example, replacing a birthdate with just the year of birth.
- Randomization – shuffling data values in a systematic way to remove identifiable patterns while preserving statistical properties. For example, adding +/- 10% noise to ages.
- Suppression – removing columns containing PII entirely rather than transforming the data. For example, deleting name and address fields.
- Aggregation – combining multiple records into summary data rather than storing individual-level data. For example, reporting statistics by ZIP code rather than address.
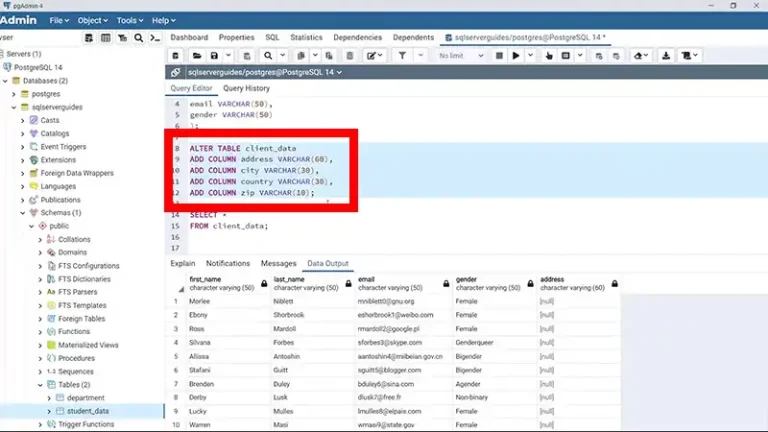
An example of anonymization would be transforming this data:
Name: Jane Doe Birthdate: 3/22/1985 Address: 123 Main St, Anytown, CA 12345
Into:
Name: [suppressed] Birth Year: 1985 Location: Anytown, CA
What is Data Masking?
Data masking obscures PII by replacing it with realistic but fake data. The original sensitive values remain stored elsewhere, allowing reversal of the masking.
Some data masking techniques include:
- Substitution – replacing PII with fake but valid data. For example, pseudonyms in place of real names.
- Shuffling – swapping original data values across records. For example, switching phone numbers between customer records.
- Number and date variance – modifying dates and numbers slightly but plausibly. For example, tweaking ages by +/- 3 years.
- Redaction – replacing PII with Xs, *s or other characters to block visibility. For example, XXX-XXX-1234 instead of phone numbers.
An example of data masking would be:
Name: Jane Doe -> Name: Betty Smith Birthdate: 3/22/1985 -> Birthdate: 4/15/1982 Address: 123 Main St, Anytown, CA 12345 -> Address: 765 Oak Rd, Anytown, CA 12345
The masked data looks realistic but does not contain real PII.
Key Differences Between Data Anonymization and Data Masking
The key differences between data anonymization and data masking can be summarized in the following table:
| Characteristic | Data Anonymization | Data Masking |
| Goal | To make data unidentifiable | To obscure sensitive data |
| Techniques | Removes or modifies PII | Replaces sensitive data with fictitious data |
| Reversibility | Not reversible | Reversible |
| Use cases | Data sharing, research, compliance | Testing, development, training |
| Data Utility | Permanently Alters Data | Retains Original Data Structure |
Differences in Use Cases for Data Anonymization and Data Masking
Data anonymization and data masking are used in a variety of different scenarios, including:
Data Sharing
When sharing data with third parties, it is important to anonymize the data to protect the privacy of individuals. For example, a company might anonymize customer data before sharing it with a research firm.
Research
Researchers often need to use large datasets containing sensitive information, such as medical records or financial data. Data anonymization allows researchers to use this data without compromising the privacy of the individuals involved.
Compliance
Many data privacy regulations, such as the General Data Protection Regulation (GDPR), require organizations to anonymize personal data before sharing it or processing it for certain purposes.
Testing and development
When testing or developing new applications, it is often necessary to use real data. However, this data can contain sensitive information, such as customer names and credit card numbers. Data masking allows developers to test and develop their applications without compromising the security of the data.
Training
Data masking is also used to train employees on how to use new applications or systems without exposing them to sensitive data.
FAQs – Frequently Asked Questions and Answers
- What are some tools and resources to help me implement data anonymization and data masking?
Answer: Open-source tools (AnonyMeizer, S anonymizer), commercial tools, and consulting services are available.
- What are some best practices for implementing data anonymization and data masking?
Answer: Use a variety of techniques, document your process, test the anonymized or masked data, and monitor it on an ongoing basis.
- How can I choose the right data anonymization and data masking techniques for my needs?
Answer: Consider the specific needs of your organization, the type of data you are protecting, and the desired level of protection.
To Conclude
Data anonymization and data masking are two important techniques for protecting sensitive data. By understanding the key differences between the two techniques and their respective use cases, you can choose the right technique for your needs and implement it in a way that ensures that your data is adequately protected.