How to Abandon a Pull Request in Azure DevOps | A Complete Guide
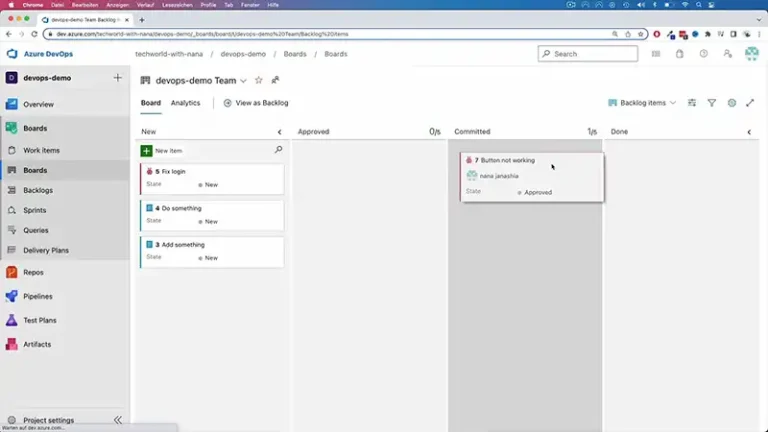
When it comes to managing your code changes in Azure DevOps, there are various scenarios where you might need to abandon a pull request without merging. Whether you’re working through a web browser, utilizing Visual Studio, or prefer command-line operations through Azure DevOps CLI, we’ve got you covered. In this article, we’ll walk you through…