Cloud Deployment Interview
What does a cloud computing expert need to know? In part one of the cloud interview guide we covered some basic unix & Linux systems administration skills, and cloud computing and infrastructure concepts. Those are key starting points. You might also want to jump to part 3 cloud dba, architecture and management interview questions.
In this second part, let’s dig into deploying applications in the cloud, and day-to-day operations skills. There’s a lot of material here. We recommend picking a few questions out of the bunch and focusing on those questions, rather than trying to cover all of them.
Also, while on the topic of hiring, keep in mind that Hiring is a Numbers Game.

Deploying in the Cloud
Deploying applications into virtual or cloud datacenters involves understanding and evaluating providers. Many just deploy on Amazon EC2 as it is far and away the largest cloud hosting solution, with the most robust offering.
Here are the questions to ask on a cloud deployment interview:
You might also like our MySQL DBA Interview Guide as well.
What Sets Amazon Apart from The Other Cloud Providers?
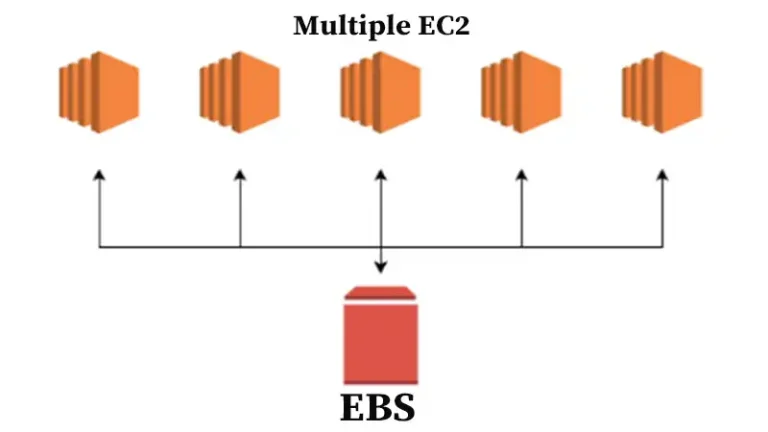
There are probably two things that set Amazon apart from other cloud infrastructure solutions. EBS or elastic block storage being one.
Although the others have storage solutions, and Rackspace is working on their own virtualized storage, Amazon seems to be the furthest ahead with its offering. It is fully virtual, allows arbitrary chunks of storage to be attached to instances, and allows instances to boot of ebs volumes.
The other major point is that since Amazon has grown so large, so quickly, it has more datacenters, in more geographically dispersed areas than other providers. Since these are organized into logical resources and can be accessed through API, it makes your application infrastructure truly virtual.
What Are Some Other Large Cloud Providers?
Joyent, Rackspace cloud, Storm on Demand, GoGrid and VoxCloud. There are certainly many others. Take a look at this Quora post: Most Reliable Cloud Providers.
Tell One Vendor Management Story.
Everyone who has managed operations, has worked with vendors at one point or another. For example, if you’ve worked with Rackspace, you know that it’s pretty easy to get a human on the line.
Amazon on the other hand allows you to do-it-yourself for everything, and only later added on a support service option. So, their service pattern and history are different.
Also check out 3 Things CEOs should know about the cloud.
How Do You Troubleshoot a Problems?
There isn’t really a right or wrong answer to this question, but it’s a nice starting point to discussion. It can also help illustrate a candidates communication skill, and how specifically they walk through solving a problem. What problem they choose as an illustration, and how they work through to a resolution is an important indicator of operations experience.
Pros and cons of Amazon versus Rackspace, configuration management & automation and cloud management solutions like Scalr and Rightscale… these and other skills are an important for a cloud deployment expert.
What Is Puppet and Chef?
Puppet is a configuration management system which allows ops teams to build templates for servers, and deploy many servers based on those templates. It further allows centralized control of configuration, to automate the management of a large number of servers.
Chef grew out of frustrations of Puppet, and is a sort of next generation configuration management system.
The term infrastructure as code may be thrown around. Since all cloud resources can be provisioned through API calls, everything in server deployment can be *theoretically* done via code, from spinup of servers, to installing packages, to configuring, code checkout, seeding databases and more.
Also our article What is Infrastructure provisioning and why is it important.
What Are Some of The Pros and Cons of Configuration Management for Operations?
Pros include allowing a smaller team to automate the deployment of a large fleet of servers, standardization, and consistency. Cons include complexity when needing to do surgical, urgent changes, and complexity when coming into an existing environment that you’ve inherited.
How Is Rightscale Different? What Does It Provide?
Rightscale is a layer on top of your cloud provider. They provide a common interface and dashboard from which to deploy servers. Templating, automation, and multi-cloud support make it a great solution for teams that have less technical expertise on staff or less hands to manage things.
How About Scalr?
They’re another management solution, that supports multiple cloud providers. They offer templating, and auto-scaling too.
While you’re here, take a look at our Myth of Five Nines – Why HA is Overrated.
Day to day skills
What Type of Programming Experience Do You Have?
The answer is that every ops guy or girl should be able to code, just as every developer should have some basic operational experience. Should and does are often two different things, so ask for some examples.
Shell Scripts
Bash, csh, Perl and Python are all part of the Linux administrators toolbox. Writing backup scripts, log rotation, automating routine tasks and so forth are all common needs of an operations expert.
Regular expressions are a part of Unix and used in scripting to search files, cronjobs, and ETL jobs. Ask for some basic examples.
What Is Continuous Integration?
The old model of code deployment was called waterfall, and allowed long careful planning, coding of new features, testing, and finally deployment. The cycle could take weeks or months and iterative change took a lot of time.
Continuous integration also known as agile deployments, allows a much more frequent in some cases many times per day deployment of changes.
What Are Metrics Good For?
Just like in website visitor tracking, and business analytics, server level analytics and tracking are possible. Collecting server metrics such as load averages, memory, disk and cpu usage over time can be invaluable.
When an application slows or server stalls, checking historical metrics can often quickly reveal problems or causes.
What are some examples? nagios, ganglia, cacti, munin, opennms
What Is Unit Testing?
This allows for software to be build in small testable compontents. When the compontents are coded, tests are also written that test whether they are operating properly, and whether dependencies are also installed and working.
Metrics, monitoring, load testing, firewalls, security & patching, Saas, Paas and IaaS there is a wide swath of skills needed to be competent as a web operations engineer. You’ve got your work cut out for you!
What Is Load Testing?
By performing some benchmarks, load testing can make estimates about how the application and code will perform when more users are hitting it.
Security & Networking
Sometimes a systems administrator is a generalized admin and sometimes there is a networking specialist on staff who doesn’t allow anyone else to touch that domain.
What Are Firewall Rules?
Unix services use port numbers to expose those services to the world. Since all servers on the internet are identified by IP addresses, firewall rules are defined around IP addresses or groups of them, and the ports they’re allowed to access.
What is DNS?
DNS stands for domain name services. This is the sort of yellow pages of the internet. DNS allows a server name to be converted to its underlying IP address. It’s a very important service for any network, and generally includes many backup servers for when the primaries experience problems.
What Is a Virtual Private Network?
A VPC provides a network link between a physical datacenter or your offices network, and your cloud provider. It allows you to elastically grow your existing datacenter using virtual resources, while treating those new boxes more like servers in your existing datacenter. IP addresses and subnets are controlled by your existing network rules and admins.
Why Is Security Important in Web Operations?
Since your business assets are primarily stored in digital form, the security of those assets depends on the security of your computer systems. Passwords, firewalls and encryption are all relevant.
Why Is Patching Software Important?
Since security is a moving target, and vulnerabilities are constantly being discovered in software, patching and updates are important. Staying fairly current in applying patches means you network and systems will be more secure.
What Is Intrusion Detection?
Bugs in software open up vulnerabilities and ways into systems. Intrusion detection attempts to detect that such intrusions and avoid further damage.
What Is Saas – Software as A Service?
An example is dropbox, and other so-called hold-my-data type solutions fall into this category.
What is Iaas – Infrastructure as a Service?
This is raw iron, the virtualized datacenters, hosting providers such as Amazon, GoGrid, Joyent, and Rackspace.
What Is Paas – Platform as A Service?
Solutions such as heroku, squarespace, wpengine and engineyard fall into this category. Some provide a platform such as the WordPress CMS, with arbitrary scaling options. Others like Heroku and EngineYard allow Ruby applications to be deployed without the need for a lot of fuss at the operational level.
Conclusion
So, that’s all the questions which can be asked during a cloud deployment interview. We’re not done yet. In part three of this series, we’ll hit on dba skills, and a series of general questions that cut across the spectrum of web operations. Or jump back to part one of the cloud interview guide.