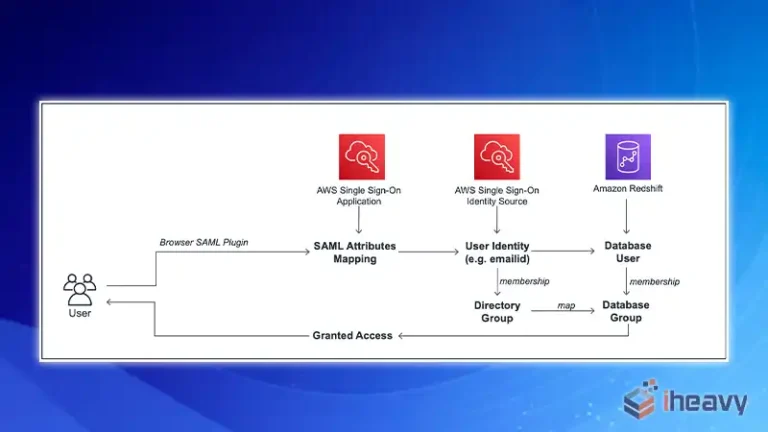
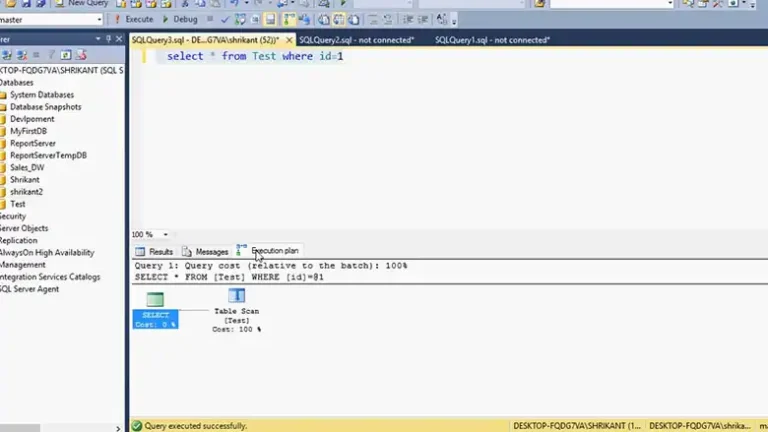
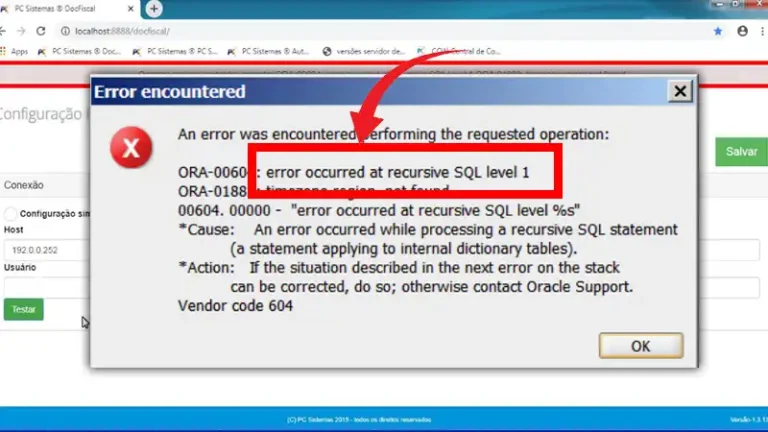
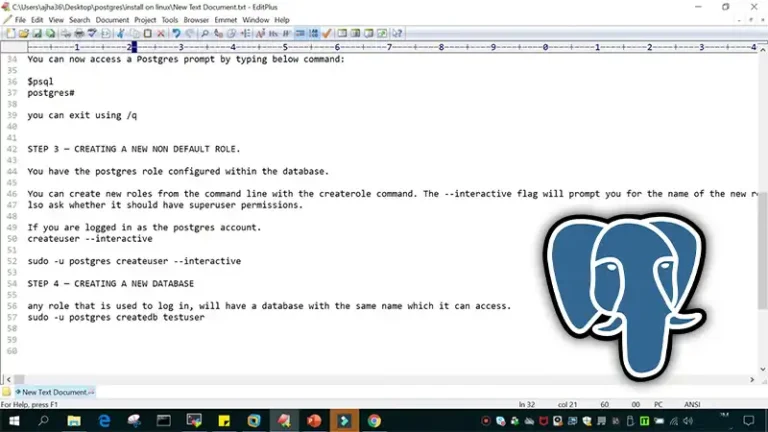
What Is the Alternative for DISTINCT Keyword in SQL?
In SQL, the DISTINCT keyword is commonly used to remove duplicate records from query results. It ensures that only unique values are returned from a column or a combination of columns. However, there are situations where DISTINCT may not be the most efficient or appropriate option, especially in complex queries or performance-critical applications. This article…