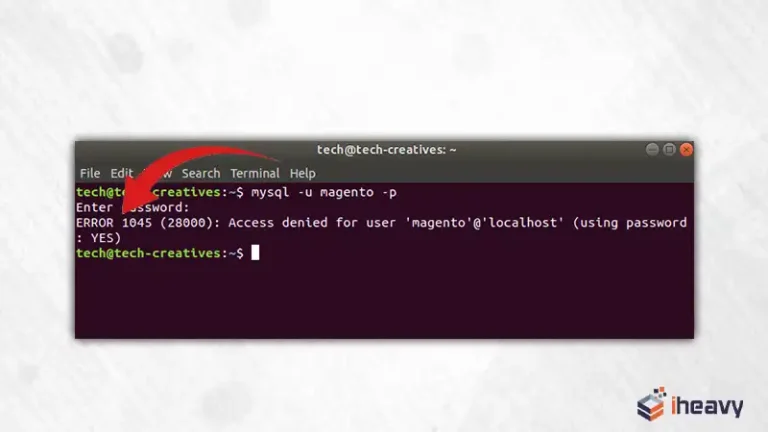
Resolving MySQL Error 1045: Access Denied for User ‘root’@’localhost’
Encountering the MySQL error 1045, which states “Access denied for user ‘root’@’localhost’”, can be frustrating, especially when attempting to access or manage your MySQL database. This error typically indicates authentication failure due to incorrect credentials or insufficient privileges. In this article, we’ll explore common causes of this error and how to troubleshoot and resolve it…