8 Questions to Ask an AWS Expert
If you’re headhunting a cloud computing expert, specifically someone who knows Amazon Web Services (AWS) and EC2, you’ll want to have a battery of questions to ask them to assess their knowledge. As with any technical interview focus on concepts and the big picture. As the 37Signals folks like to say “hire for attitude, train for skill”. Absolutely!
New: Top questions for hiring a serverless lambda expert
Also new: Top questions to ask on a devops expert interview
If you want more general info about Amazon Web Services, read our Intro to EC2 Deployments.

Question 1: What Is Elastic Block Storage?
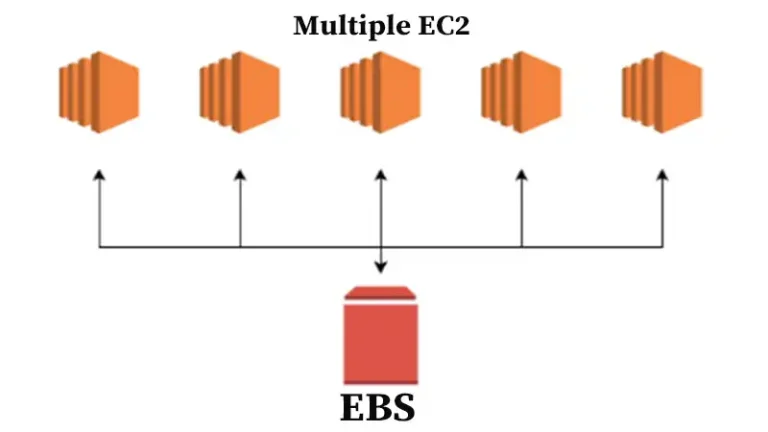
EBS is a virtualized SAN or storage area network. That means it is RAID storage to start with so it’s redundant and fault tolerant. If disks die in that RAID, you don’t lose data. Great! It is also virtualized, so you can provision and allocate storage, and attach it to your server with various API calls. No calling the storage expert and asking him or her to run specialized commands from the hardware vendor.
What Type of Performance Can You Expect?
Performance on EBS can exhibit variability. That is, it can go above the SLA performance level, then drop below it. The SLA provides you with an average disk I/O rate you can expect. This can frustrate some folks, especially performance experts who expect reliable and consistent disk throughput on a server. Traditional physically hosted servers behave that way. Virtual AWS instances do not.
Related: Is Amazon too big to fail?
How Do You Back It Up?
Backup EBS volumes by using the snapshot facility via an API call or via a GUI interface like Elasticfox.
How Do You Improve Performance?
Improve performance by using Linux software raid and striping across four volumes.
Question 2: What Is S3? What Is It Used For? Should Encryption Be Used?
S3 stands for Simple Storage Service. You can think of it like ftp storage, where you can move files to and from there, but not mount it like a filesystem. AWS automatically puts your snapshots there, as well as AMIs there. Encryption should be considered for sensitive data, as S3 is a proprietary technology developed by Amazon themselves, and as yet unproven vis-a-vis a security standpoint.
Question 3: What is an AMI?
AMI stands for Amazon Machine Image. It is effectively a snapshot of the root filesystem. Commodity hardware servers have a bios that points the the master boot record of the first block on a disk. A disk image though can sit anywhere physically on a disk, so Linux can boot from an arbitrary location on the EBS storage network.
How Do I Build One?
Build a new AMI by first spinning up and instance from a trusted AMI. Then adding packages and components as required. Be wary of putting sensitive data onto an AMI. For instance your access credentials should be added to an instance after spinup. With a database, mount an outside volume that holds your MySQL data after spinup as well.
Question 4: Can I Vertically Scale an Amazon Instance & How?
Yes. This is an incredible feature of AWS and cloud virtualization. Spinup a new larger instance than the one you are currently running. Pause that instance and detach the root ebs volume from this server and discard. Then stop your live instance, and detach its root volume. Note the unique device ID and attach that root volume to your new server. And then start it again. Voila, you have scaled vertically in place!!
Question 5: What Is Auto-Scaling & How Does It Work?
Autoscaling is a feature of AWS which allows you to configure and automatically provision and spinup new instances without the need for your intervention. You do this by setting thresholds and metrics to monitor. When those thresholds are crossed a new instance of your choosing will be spun up, configured, and rolled into the load balancer pool. Voila, you’ve scaled horizontally without any operator intervention!
Also: Are we fast approaching cloud-mageddon?
With MySQL databases autoscaling can get a little dicey, so we wrote a guide to autoscaling MySQL on amazon EC2.
Question 6: What Automation Tools Can I Use to Spinup Servers?
The most obvious way is to roll-your-own scripts, and use the AWS API tools. Such scripts could be written in bash, python or another language or your choice. Next option is to use a configuration management and provisioning tool like puppet or better its successor Opscode Chef.
Ansible is also an excellent option because it doesn’t require an agent, and can run your shell scripts as-is. You might also look towards CloudFormation or Terraform. The resulting code captures your entire infrastructure and can be checked into your git repository & version controlled. You can even unit test this way!
Question 7: What Is Configuration Management?
Configuration management has been around for a long time in web operations and systems administration. Yet the cultural popularity of it has been limited. Most systems administrators configure machines as the software was developed before version control – that is manually making changes on servers.
Each server can then and usually be slightly different. Troubleshooting though is straightforward as you log in to the box and operate on it directly.
Why Would I Want to Use It with Cloud Provisioning of Resources?
Configuration management brings a large automation tool into the picture, managing servers like strings of a puppet. This forces standardization, best practices, and reproducibility as all configs are versioned and managed. It also introduces a new way of working which is the biggest hurdle to its adoption.
Read: When hosting data on Amazon turns bloodsport
Enter the cloud, and configuration management becomes even more critical. That’s because virtual servers such as amazons EC2 instances are much less reliable than physical ones. You absolutely need a mechanism to rebuild them as-is at any moment. This pushes best practices like automation, reproducibility, and disaster recovery into center stage.
While on the subject of configuration management take a quick peek at hiring a devops guide.
Question 8: Explain How You Would Simulate Perimeter Security Using Amazon Web Services Model?
Traditional perimeter security that we’re already familiar with using firewalls and so forth is not supported in the Amazon EC2 world. AWS supports security groups. One can create a security group for a jump box with ssh access – only port 22 open.
From there a webserver group and database group are created. The webserver group allows 80 and 443 from the world, but port 22 *only* from the jump box group.
Further the database group allows port 3306 from the webserver group and port 22 from the jump box group. Add any machines to the webserver group and they can all hit the database. No one from the world can, and no one can directly ssh to any of your boxes.
The more full featured way to go is VPC. That’s Amazon’s acronym for virtual private cloud. You can create virtual networks both private & public, with subnets, etc. all within VPCs. You then spinup servers & resources inside those virtual networks. VPCs can be controlled with security groups or the more powerful but messy access control lists.
Want to further lock this configuration down? Only allow ssh access from specific IP addresses on your network, or allow just your subnet.
Conclusion
That’s all the 8 questions that you can ask an AWS expert during an interview or you need to know as an AWS expert. Hopefully, you’ve found this article helpful; And if you have anything to ask regarding this topic, feel free to leave a comment in our comment section below. Thanks for reading!