DATABASE MANAGEMENT Database Management WinHTTP Callback Status Request Error gRPC | EVERYTHING YOU NEED TO KNOW ByNolan Granger March 10, 2024March 9, 2024 SQL Database Management Postgresql Vs Sql Server | Similarities and Dissimilarities ByNolan Granger January 16, 2024January 15, 2024 Database Management Database Schema Migration Best Practices | Challenges and Principles Focused ByNolan Granger December 30, 2023December 30, 2023 Database Management How to Install Oracle 21C Express Edition on Windows 11 | Step-by-Step Guide ByNolan Granger December 30, 2023December 30, 2023 Database Management How to Get Only Date from SYSDATE in Oracle ByNolan Granger December 30, 2023December 30, 2023 SQL Database Management Database Operations Connection or SQL Sentence Error DA0005: Causes and Troubleshooting Steps ByNolan Granger December 27, 2023December 27, 2023 Database Management SQL ORA-00907 Missing Right Parenthesis in Oracle Fusion | Explained and Solved ByNolan Granger December 23, 2023December 23, 2023 Database Management Azure Event Hub vs Event Grid | Comparison Guide ByNolan Granger December 11, 2023December 11, 2023 Database Management Understanding And Resolving “Cannot Initialize The Data Source Object Of Ole Db Provider” Error ByNolan Granger December 11, 2023December 11, 2023 Devops Devops How to Abandon a Pull Request in Azure DevOps | A Complete Guide ByNolan Granger December 30, 2023December 30, 2023 Devops AWS Is AWS DevOps Certification Worth It | Explained ByNolan Granger December 30, 2023December 30, 2023 Devops Aws Solutions Architect Vs DevOps Engineer || Why they are not the same? ByNolan Granger December 27, 2023December 27, 2023 Devops How to Create User Story in Azure DevOps? A Step-by-Step Guide ByNolan Granger December 2, 2023December 2, 2023 Devops What Distinguishes A Saas Platform From Regular Software Applications? ByNolan Granger November 30, 2023November 30, 2023 Database Management Devops Scalability and Performance Is Automation Killing Old-School operations? ByNolan Granger August 17, 2023October 11, 2023 Devops Scalability and Performance Is There a Serious Skills Shortage Around DevOps Space? ByNolan Granger August 17, 2023October 11, 2023 Devops When Should I Use Ansible Versus Packer or Terraform? ByNolan Granger August 17, 2023October 11, 2023 AWS Devops Scalability and Performance Does AWS Have a Dirty Little Secret? ByNolan Granger August 16, 2023October 11, 2023 Cloud Computing Cloud Computing What Is A Difference Between The Functions Of Cloud Computing And Virtualization? [Answered] ByNolan Granger March 9, 2024March 9, 2024 Cloud Computing In Depth Comparison of Security Issues: Public Vs Private Vs Hybrid Cloud Computing ByGary Kee February 13, 2024February 7, 2024 Cloud Computing Factors or Considerations for Choosing a Cloud Service Model | ULTIMATE EXPLANATION ByNolan Granger January 15, 2024January 15, 2024 Cloud Computing How Is the Development of SaaS Related to Cloud Computing | Explained ByNolan Granger December 30, 2023December 30, 2023 Cloud Computing How to Use Terraform Console: Getting Started ByNolan Granger December 30, 2023December 30, 2023 Cloud Computing What Are the Benefits of Using Terraform? | Six Explained ByNolan Granger December 30, 2023December 30, 2023 Cloud Computing | AWS How Hard Is Aws Cloud Practitioner Exam | For Beginner Or Expert? ByNolan Granger December 27, 2023December 27, 2023 Cloud Computing Basic Components of Cloud Computing: Demystifying the Cloud ByNolan Granger December 27, 2023December 27, 2023 Cloud Computing What Is Caas In Cloud Computing || Understanding CAAS? ByNolan Granger December 26, 2023December 26, 2023 AWS AWS Is AWS Solution Architect Worth It | Answered ByNolan Granger March 19, 2024March 17, 2024 AWS [Answered] How To Migrate A Website To AWS? ByGary Kee February 21, 2024February 18, 2024 AWS Request Failed With Status Code 403 AWS Lambda | 11 Ways to Fix ByNolan Granger December 30, 2023December 30, 2023 AWS How to Setup an Amazon ECS Cluster With Terraform | Step-by-Step Guide ByNolan Granger December 30, 2023December 30, 2023 AWS What Is Routing Table in AWS | A Complete Guide ByNolan Granger December 30, 2023December 30, 2023 AWS AWS S3 Check if File Exists | Simplified ByNolan Granger December 30, 2023December 30, 2023 AWS How Long Do Terminated Instances Stay in AWS? ByNolan Granger December 30, 2023December 30, 2023 Devops | AWS Is AWS DevOps Certification Worth It | Explained ByNolan Granger December 30, 2023December 30, 2023 AWS How to Migrate On-Premise Server to AWS Step by Step | 8 Step Guideline ByNolan Granger December 30, 2023December 30, 2023 Scalability and Performance Scalability and Performance Webrootpath vs Contentrootpath | Comparison Guide ByNolan Granger March 22, 2024March 20, 2024 Scalability and Performance VPC Peering vs Privatelink | Differences ByNolan Granger March 12, 2024March 9, 2024 Scalability and Performance Does Git Pull Overwrite Local Changes | Answered ByNolan Granger March 11, 2024March 9, 2024 Scalability and Performance How to Delete AMI in AWS ByGary Kee February 7, 2024 Scalability and Performance Can You Work in Data Analytics Without a Degree | Breaking Barriers ByNolan Granger January 26, 2024January 26, 2024 Scalability and Performance How To Group By Month In SQL (Steps to Create) ByNolan Granger January 15, 2024January 15, 2024 Scalability and Performance Can I Create a Virtual Directory in web.config? ByNolan Granger December 30, 2023December 30, 2023 Scalability and Performance How to Terraform in Stellaris 2.2 | A Complete Guide ByNolan Granger December 30, 2023December 30, 2023 Scalability and Performance What Does Terraform Init Do | Explained ByNolan Granger December 30, 2023December 30, 2023
Database Management WinHTTP Callback Status Request Error gRPC | EVERYTHING YOU NEED TO KNOW ByNolan Granger March 10, 2024March 9, 2024
SQL Database Management Postgresql Vs Sql Server | Similarities and Dissimilarities ByNolan Granger January 16, 2024January 15, 2024
Database Management Database Schema Migration Best Practices | Challenges and Principles Focused ByNolan Granger December 30, 2023December 30, 2023
Database Management How to Install Oracle 21C Express Edition on Windows 11 | Step-by-Step Guide ByNolan Granger December 30, 2023December 30, 2023
Database Management How to Get Only Date from SYSDATE in Oracle ByNolan Granger December 30, 2023December 30, 2023
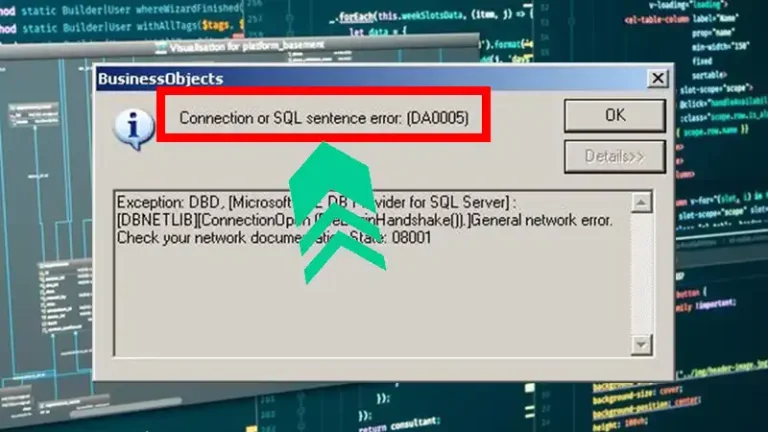
SQL Database Management Database Operations Connection or SQL Sentence Error DA0005: Causes and Troubleshooting Steps ByNolan Granger December 27, 2023December 27, 2023
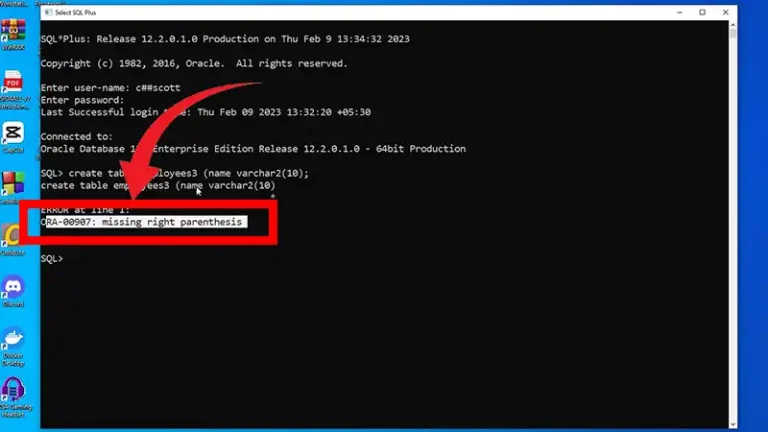
Database Management SQL ORA-00907 Missing Right Parenthesis in Oracle Fusion | Explained and Solved ByNolan Granger December 23, 2023December 23, 2023
Database Management Azure Event Hub vs Event Grid | Comparison Guide ByNolan Granger December 11, 2023December 11, 2023
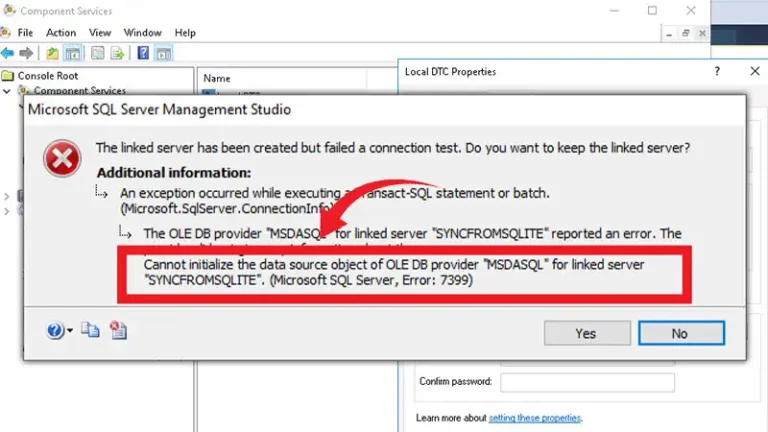
Database Management Understanding And Resolving “Cannot Initialize The Data Source Object Of Ole Db Provider” Error ByNolan Granger December 11, 2023December 11, 2023
Devops How to Abandon a Pull Request in Azure DevOps | A Complete Guide ByNolan Granger December 30, 2023December 30, 2023
Devops AWS Is AWS DevOps Certification Worth It | Explained ByNolan Granger December 30, 2023December 30, 2023
Devops Aws Solutions Architect Vs DevOps Engineer || Why they are not the same? ByNolan Granger December 27, 2023December 27, 2023
Devops How to Create User Story in Azure DevOps? A Step-by-Step Guide ByNolan Granger December 2, 2023December 2, 2023
Devops What Distinguishes A Saas Platform From Regular Software Applications? ByNolan Granger November 30, 2023November 30, 2023
Database Management Devops Scalability and Performance Is Automation Killing Old-School operations? ByNolan Granger August 17, 2023October 11, 2023
Devops Scalability and Performance Is There a Serious Skills Shortage Around DevOps Space? ByNolan Granger August 17, 2023October 11, 2023
Devops When Should I Use Ansible Versus Packer or Terraform? ByNolan Granger August 17, 2023October 11, 2023
AWS Devops Scalability and Performance Does AWS Have a Dirty Little Secret? ByNolan Granger August 16, 2023October 11, 2023
Cloud Computing What Is A Difference Between The Functions Of Cloud Computing And Virtualization? [Answered] ByNolan Granger March 9, 2024March 9, 2024
Cloud Computing In Depth Comparison of Security Issues: Public Vs Private Vs Hybrid Cloud Computing ByGary Kee February 13, 2024February 7, 2024
Cloud Computing Factors or Considerations for Choosing a Cloud Service Model | ULTIMATE EXPLANATION ByNolan Granger January 15, 2024January 15, 2024
Cloud Computing How Is the Development of SaaS Related to Cloud Computing | Explained ByNolan Granger December 30, 2023December 30, 2023
Cloud Computing How to Use Terraform Console: Getting Started ByNolan Granger December 30, 2023December 30, 2023
Cloud Computing What Are the Benefits of Using Terraform? | Six Explained ByNolan Granger December 30, 2023December 30, 2023
Cloud Computing | AWS How Hard Is Aws Cloud Practitioner Exam | For Beginner Or Expert? ByNolan Granger December 27, 2023December 27, 2023
Cloud Computing Basic Components of Cloud Computing: Demystifying the Cloud ByNolan Granger December 27, 2023December 27, 2023
Cloud Computing What Is Caas In Cloud Computing || Understanding CAAS? ByNolan Granger December 26, 2023December 26, 2023
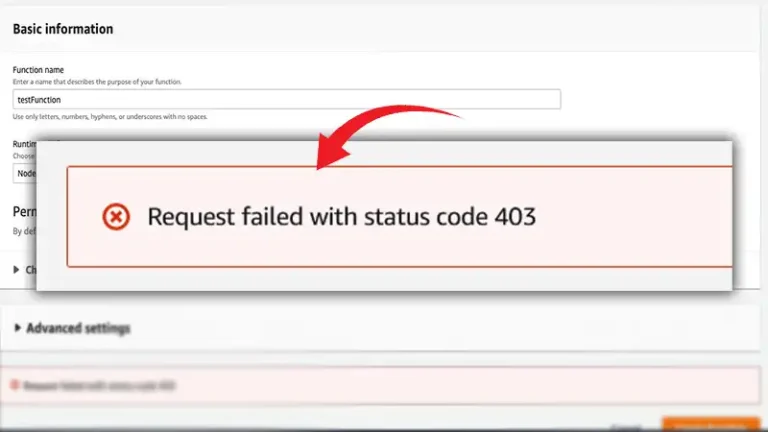
AWS Request Failed With Status Code 403 AWS Lambda | 11 Ways to Fix ByNolan Granger December 30, 2023December 30, 2023
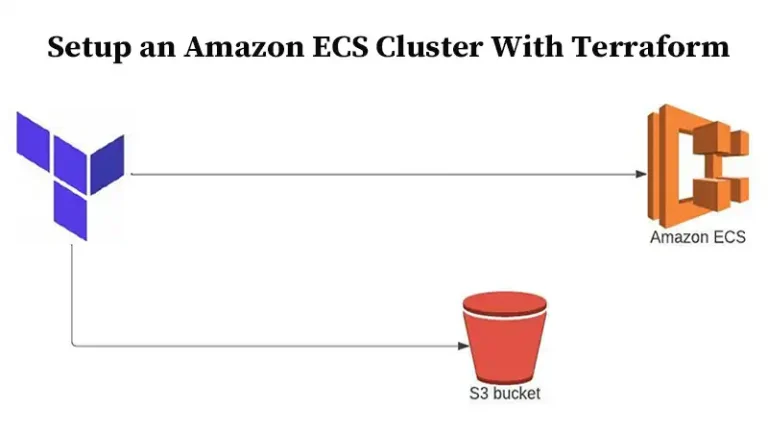
AWS How to Setup an Amazon ECS Cluster With Terraform | Step-by-Step Guide ByNolan Granger December 30, 2023December 30, 2023
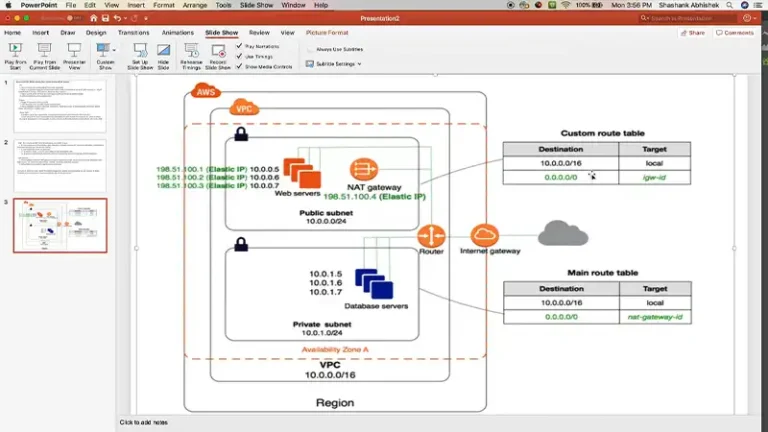
AWS What Is Routing Table in AWS | A Complete Guide ByNolan Granger December 30, 2023December 30, 2023
Devops | AWS Is AWS DevOps Certification Worth It | Explained ByNolan Granger December 30, 2023December 30, 2023
AWS How to Migrate On-Premise Server to AWS Step by Step | 8 Step Guideline ByNolan Granger December 30, 2023December 30, 2023
Scalability and Performance Webrootpath vs Contentrootpath | Comparison Guide ByNolan Granger March 22, 2024March 20, 2024
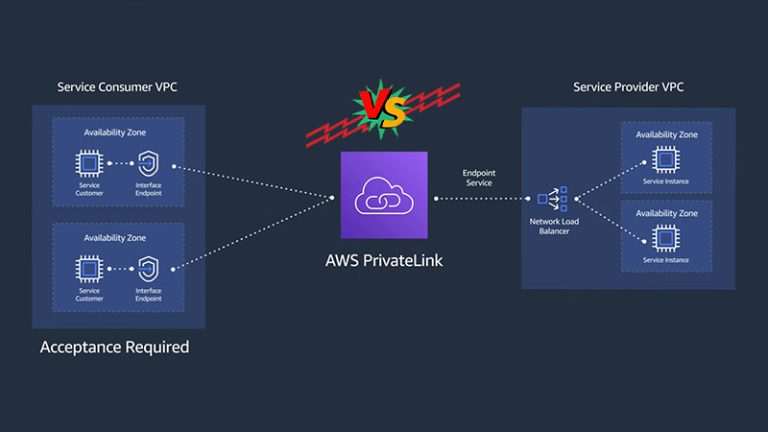
Scalability and Performance VPC Peering vs Privatelink | Differences ByNolan Granger March 12, 2024March 9, 2024
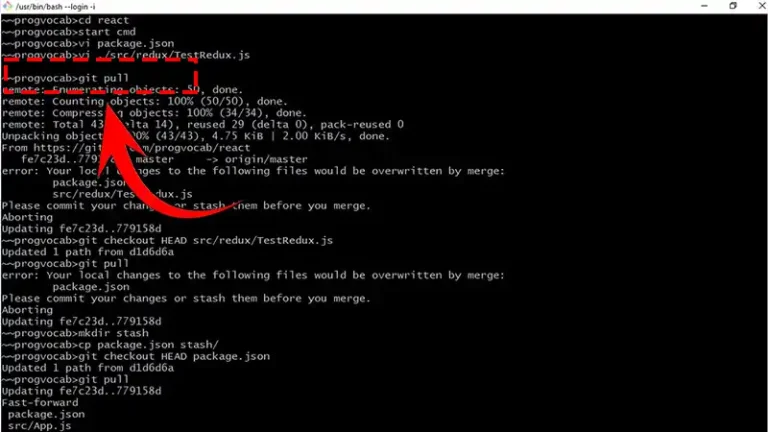
Scalability and Performance Does Git Pull Overwrite Local Changes | Answered ByNolan Granger March 11, 2024March 9, 2024
Scalability and Performance Can You Work in Data Analytics Without a Degree | Breaking Barriers ByNolan Granger January 26, 2024January 26, 2024
Scalability and Performance How To Group By Month In SQL (Steps to Create) ByNolan Granger January 15, 2024January 15, 2024
Scalability and Performance Can I Create a Virtual Directory in web.config? ByNolan Granger December 30, 2023December 30, 2023
Scalability and Performance How to Terraform in Stellaris 2.2 | A Complete Guide ByNolan Granger December 30, 2023December 30, 2023
Scalability and Performance What Does Terraform Init Do | Explained ByNolan Granger December 30, 2023December 30, 2023